Institution
Universitat de Barcelona
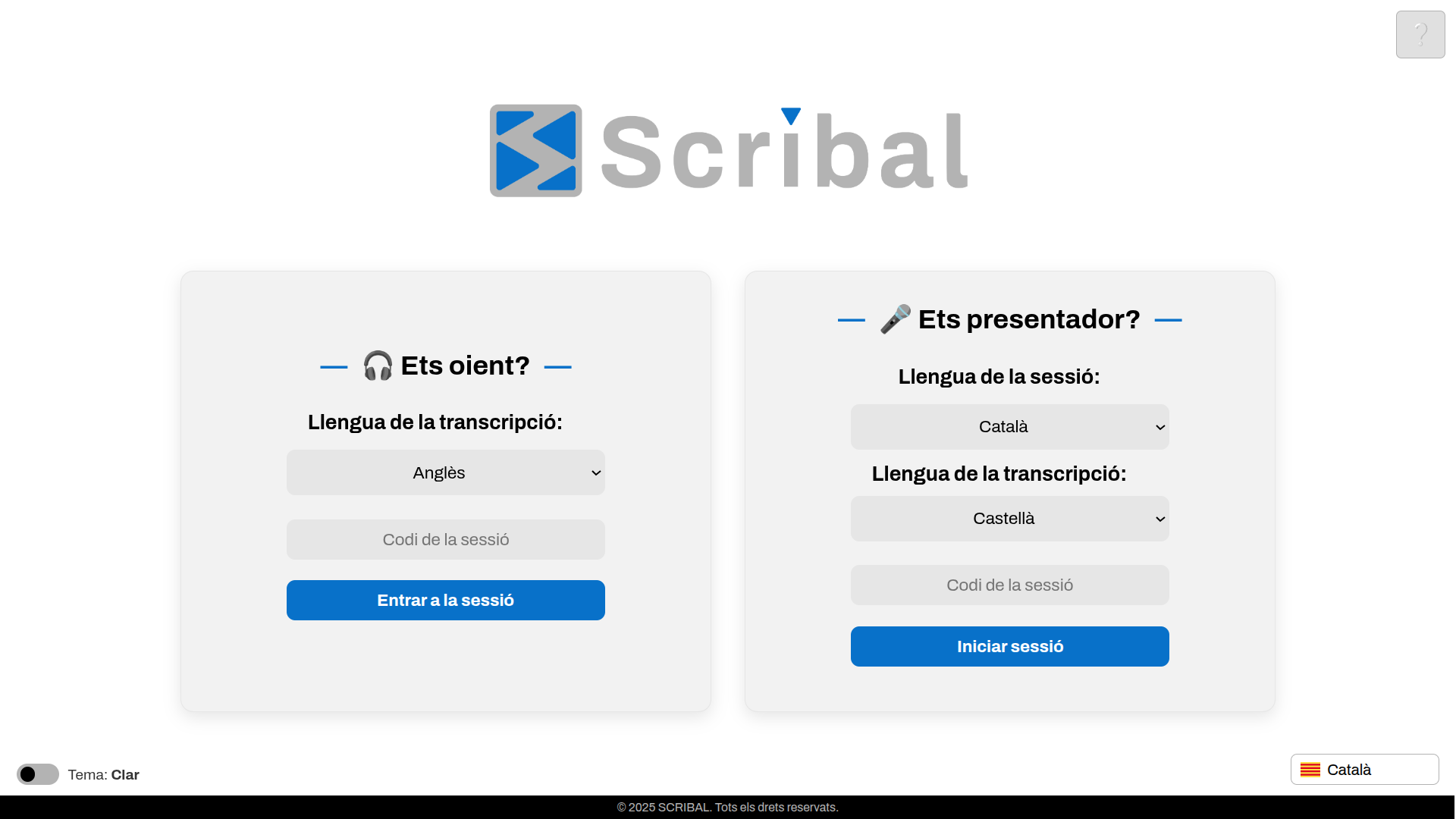
Speech-to-text technology, appropriate for uses in which privacy is essential or when high performance levels are required for a specific domain.
Unlike cloud-based solutions, this system operates locally, ensuring that sensitive data are not sent through the internet. It uses deep neural networks such as Whisper (at present), Wav2Vec or DeepSpeech for transcription. It can be trained with data for a specific domain and personalised with your own voice or voices from a specific accent or dialect. In addition, it includes a module adapted for people with non-fluent speech (Down syndrome and cerebral palsy).
This domain-specific speech transcription technology has great potential in digital accessibility, as it provides more precise, natural, and secure tools. Some of the specific features are:
- Voice assistants for persons with motor disabilities
- Transcription programmes for the deaf and hard of hearing
- Predictive text for persons with motor disabilities
- Adaptive learning
- Adaptation to dialects or regional accents
You can see how the technology works in The AccessCat Demos [in Catalan].
- Technology
- Easy Reading - Clear Communication
- Digital Accessibility
If you would like more information, please contact us with the reference 'SCRIBAL.'